使用 Group By,已是耗費資源的動作。若再搭配 函數等運算,勢必耗損更多系統資源。
Rewrite and optimize 優化改寫 為 多段式 Group By 來提升效能
藉由 多段式 Group By:
- 第 1 段 Group By,並 未 搭配 函數 等運算,相對輕量地執行 Group By 後,縮減 資料列筆數。
- 第 2 段 Group By,雖然搭配 函數 等耗用資源的運算,但要處理資料量卻是 遠小 於原本的資料表。
多段式的 Group By 雖然稍為增加 T-SQL 陳述式的複雜性,但卻確實有 提升效能。
| 項目 | 單一 Group By | 多段式 Group By | 比較 |
| T-SQL 陳述式 | 簡單 | 稍嫌複雜 | |
| Elapsed Time(sec) | 0.196690000 | 0.127646000 | 節省 35% |
| CPU Time(sec) | 0.018490000 | 0.013201000 | 節省 29% |
| Subtree Cost | 0.405689 | 0.182843 | 節省 55% |
-- Rewrite and optimize

本文包含討論 2 個 系統內部的暫存資料表: 'Worktable' 與 'Workfile'
- Workfile
- 用來儲存 hash joins (雜湊聯結) 與 hash aggregates (雜湊彙總) 的暫存結果。
- Worktable
- 用來儲存 Query spool (查詢多工緩衝處理)、lob 變數、XML 變數 與 Cursor (資料指標) 的暫存結果。
- 例如: GROUP BY、 ORDER BY或 UNION 查詢等。
[Performance Tuning] Multi-section of Group By clause
01. 檢視資料表內的資料
- Table: Sales.SalesOrderHeader
- Column: SalesPersonID, OrderDate, SubTotal
- rows: 31465
-- figure 01_Look_at_ data

02. 檢視 資料表上的 Index 資訊
- composite index with Included Columns: IX_SalesPersonID_OrderDate_Temp
- [SalesPersonID] , [OrderDate]
- 內含資料行的索引(Indexes with Included Columns): ([SubTotal])
-- figure 02_Index_Information

03. 彙總: 各個月份的小計(Sub Total)
- GROUP BY 這 3 個:
- SalesPersonID, YEAR(OrderDate), MONTH(OrderDate)
- 使用到 2 個 資料行: SalesPersonID, OrderDate
- 其中,OrderDate 都有搭配使用 日期 函數。以此 分組 來取得 年、月 的匯總資料。
-- figure 11_Group_By_Year_Month_OrderDate

04. 檢視 Execution Plan
- Subtree Cost: 0.405689
- rows: 461
- 主要耗用資源的 Operator(運算子)是: Index Scan(31%) + Hash Match(63%)
- Operator: Hash Match(Aggregate),占用 Execution Plan 整體的 63% 資源。
若要優化效能,該如何下手?
沒有 Missing Index 的輔助建議,還能做什麼?
-- figure 12_Hash_Match_Aggregate_ExecutionPlan

05. 觀察 Performance Data
- LastElapsedTime(sec): 0.196690000
- LastCPUTime(sec): 0.018490000
- LastLogicalReads: 119
- LastPhysicalRead: 125
- LastRows: 461
-- figure 13_Performance_Data
06. 檢視 STATISTICS IO, TIME 輸出的資訊:
- 有 2 個 系統內部的暫存資料表: Table 'Worktable' 與 Table 'Workfile'
認識 Workfiles
- 用來儲存 hash joins(雜湊聯結) 與 hash aggregates(雜湊彙總) 的暫存結果。
- work files could be used to store temporary results for hash joins and hash aggregates.
Hash joins(雜湊聯結) 用於處理 大型、未排序、無索引 的輸入。
在 複雜查詢 下,Hash joins 有利於 intermediate results(中繼結果) 的使用:
- 一般而言,中繼結果 是沒有索引 (除非有明確地儲存到磁碟,然後建立索引)。
- 通常產生時也不會做 適當的 排序 供 Execution Plan 的下一個作業使用。
- Query optimizer 只估計 中繼結果 的大小。
- 因為 複雜查詢 的 估計值 可能非常不準確,所以處理 中繼結果 的演算法必須要有效率,
- 而且萬一 中繼結果 顯著大於預期時,它的效能還不得 惡化 得太明顯。
若有 Index 可用,資料已經 排序,將可避免使用 Hash joins,避免產生 Workfiles 。
- 用來儲存 query spool (查詢多工緩衝處理)、lob 變數、XML 變數 與 Cursor (資料指標) 的暫存結果。
- work tables could be used to store temporary results for query spool, lob variables, XML variables, and cursors.
- 關聯式引擎在執行 SQL 陳述式中所指定的邏輯作業前,可能需要先建立一個 Worktables。
- Worktables 屬於 內部資料表,可用來保存 中繼結果。
- Worktables 會針對特定的 GROUP BY、 ORDER BY或 UNION 查詢而產生。
- 例如,如果 ORDER BY 子句會參考不在任何索引範圍內的資料行,則關聯式引擎可能需要產生 Worktables,根據所要求的順序來排序結果集。
- Worktables 有時候也當作 多工緩衝 處理使用,可 暫時 保存 執行部份 查詢計畫的結果。
- Worktables 建置於 tempdb 中,並且會在不再需要時 自動卸除。
-- figure 14_STATISTICS IO_TIME

Multi-section of Group By clause 多段式 Group By
01. 改寫為 多段式的 Group By
- 第 1 段 Group By
- 使用 2 個 資料行: SalesPersonID, OrderDate。
- 但 OrderDate 沒有 函數 運算。
- 第 2 段 Group By
- 使用 3 個 資料行: SalesPersonID, YEAR(OrderDate), MONTH(OrderDate)
- OrderDate 資料行,皆使用 函數 運算。依據 年、月 來分組。
-- figure 21_Multi-section of Group By clause

02. 觀察 Execution Plan,與先前已有所不同:
- Subtree Cost 降低 為: 0.182843
- rows: 461
- 主要耗用資源的 Operator(運算子)是: Index Scan(68%) + Sort (21%)
請留意:
- 已不復見 Operator: Hash Match(Aggregate)
-- figure 22_ExecutionPlan
03. 觀察 Performance Data
- LastElapsedTime(sec): 0.127646000
- LastCPUTime(sec): 0.013201000
- LastLogicalReads: 119
- LastPhysicalRead: 125
- LastRows: 461
比較先前的 GROUP BY 陳述式,LastElapsedTime(sec) 與 LastCPUTime(sec) 都 降低 了。
-- figure 25_Performance_Data
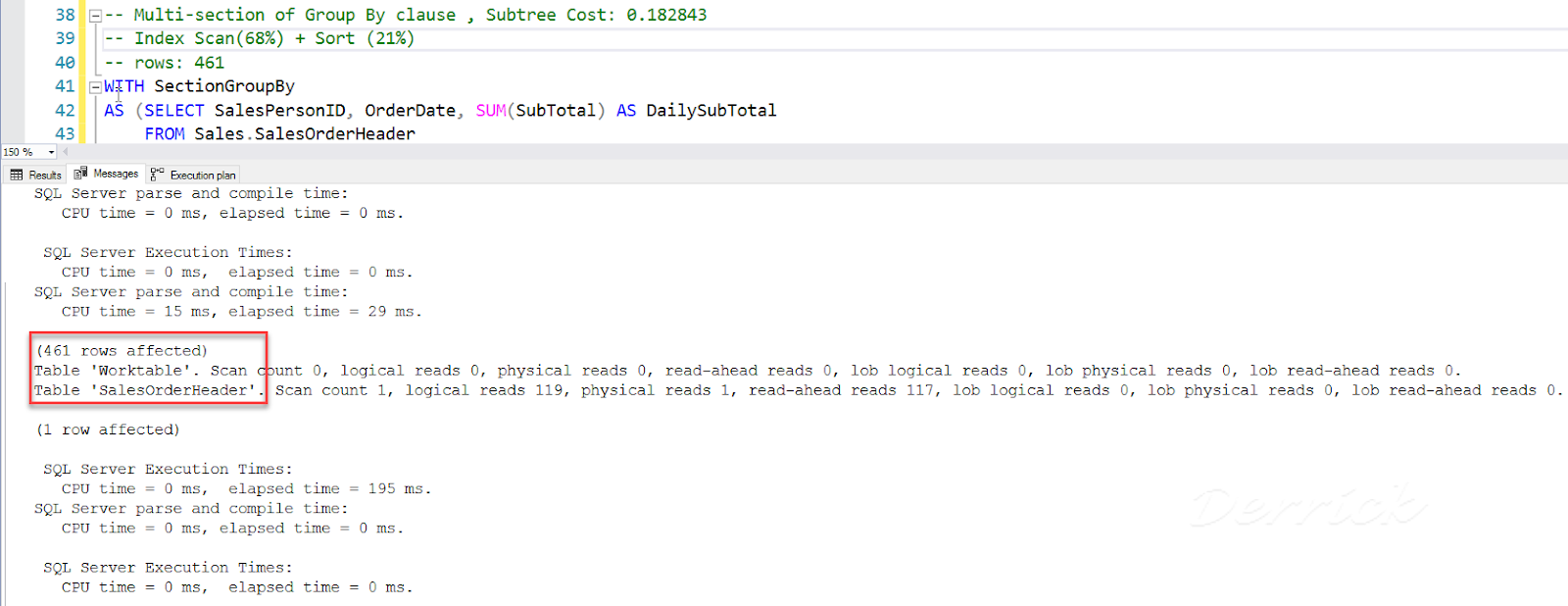
04. 檢視 STATISTICS IO, TIME 輸出的資訊:
- 僅使用到 1 個系統內部暫存資料表: 'Worktable'
已省去使用 Workfiles
- Workfiles 用於存放 hash joins 與 hash aggregates 的暫存結果。
- 改寫為 多段式 Group By,節省系統資源,省去使用 Workfiles。
-- figure 26_STATISTICS IO_TIME
05. 檢視第 1 段 Group By
- 使用到 2 個 資料行: SalesPersonID, OrderDate
- 但 OrderDate 沒有 函數 運算。
- 原本資料表有 31,465 rows,經過 GROUP BY 分組後,已 縮減 輸出為 1,592 rows。
- 資料列筆數 減量 95% ,只剩下原來的 5%。
-- figure 23_First_section

06. 檢視第 1 段 Group By 的 Execution Plan。
-- figure 24_First_section_Execution Plan

07. 比較兩者
-- figure 41_Compare_TSQL

-- figure 42_Plan_Explorer
-- figure 43_Single_Group_By_Top_Operations

-- figure

-- figure 31_Compare_Execution Plan

結論
多段式的 Group By 雖然稍為增加 T-SQL 陳述式的複雜性,但卻確實有 提升效能。
| 項目 | 單一 Group By | 多段式 Group By | 比較 |
| T-SQL 陳述式 | 簡單 | 稍嫌複雜 | |
| Elapsed Time(sec) | 0.196690000 | 0.127646000 | 節省 35% |
| CPU Time(sec) | 0.018490000 | 0.013201000 | 節省 29% |
| Subtree Cost | 0.405689 | 0.182843 | 節省 55% |
多段式 Group By 的說明如下:
第 1 段 Group By
- 使用到 2 個 資料行: SalesPersonID, OrderDate
- 但 OrderDate 沒有 函數 運算。
- 原本資料表有 31,465 rows,經過 GROUP BY 分組後,已 縮減 輸出為 1,592 rows。
- 資料列筆數 減量 95% ,只剩下原來的 5%。
第 2 段 Group By
- 對 少量 筆數的資料,執行 Group By
對資料表執行 Group By,已是耗費資源的動作。若再搭配 函數等運算,勢必耗損更多系統資源。
藉由 多段式 Group By:
- 第 1 段 Group By,並 未 搭配 函數 等運算,相對輕量地執行 Group By 後,縮減 資料列筆數。
- 第 2 段 Group By,雖然搭配 函數 等耗用資源的運算,但要處理資料量卻是 遠小 於原本的資料表。
Sample Code
20180623_Multi-section of Group By
https://drive.google.com/drive/folders/0B9PQZW3M2F40OTk3YjI2NTEtNjUxZS00MjNjLWFkYWItMzg4ZDhhMGIwMTZl?usp=sharing
Reference
Understanding Hash Joins
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008/ms189313(v=sql.100)
Advanced Query Tuning Concepts
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008/ms191426(v=sql.100)
SQL Server, Access Methods Object
https://docs.microsoft.com/en-us/sql/relational-databases/performance-monitor/sql-server-access-methods-object?view=sql-server-2017
Query Processing Architecture Guide -- Worktables
https://docs.microsoft.com/en-us/sql/relational-databases/query-processing-architecture-guide?view=sql-server-2017
Memory Management Architecture Guide -- Workfile
https://docs.microsoft.com/en-us/sql/relational-databases/memory-management-architecture-guide?view=sql-server-2017
Sort Warnings Event Class
https://docs.microsoft.com/en-us/sql/relational-databases/event-classes/sort-warnings-event-class?view=sql-server-2017
Hash Warning Event Class
https://docs.microsoft.com/en-us/sql/relational-databases/event-classes/hash-warning-event-class?view=sql-server-2017
Understanding Hash joins
https://docs.microsoft.com/en-us/sql/relational-databases/performance/joins?view=sql-server-2017
SQL Server 2012:DATEFROMPARTS 從各自部分取得日期和時間值的函數
http://sharedderrick.blogspot.com/2013/01/sql-server-2012datefromparts.html
沒有留言:
張貼留言