應用場合,例如:
轉檔作業:利用資料類型:rowversion,找出此資料列是否有被更新過,以及是否為新增的資料列。
用於實作「開放式並行存取控制(optimistic concurrency control)」。
由前台程式可用來偵測更新衝突(Update Collisions)。
您可以利用資料列的 rowversion 資料行來輕易判斷上次讀取資料列之後,資料列中的任何值是否有任何改變。
如果資料列有了任何改變,就會更新資料列版本值。
如果資料列沒有任何改變,資料列版本值就與先前讀取時相同。
若要傳回資料庫目前的資料列版本值,請使用 @@DBTS。
您可以將 rowversion 資料行加入至資料表,以確保能在多個使用者同時更新資料列時維護資料庫的完整性。
您可能也想在不必重新查詢資料表的情況下,知道更新了多少資料列以及更新了哪些資料列。
認識 資料類型:rowversion的基礎功能
-- P01_查詢-目前資料庫的目前 rowversion 資料類型值
-- P02_資料行rowversion,自動產生的唯一的二進位數字
-- P03_加入對資料類型 rowversion 的排序
-- P04_資料行 pid 值為 C,,其 rowrev 值是 0x00000000000007D3
-- P05_rowversion值,自動更新
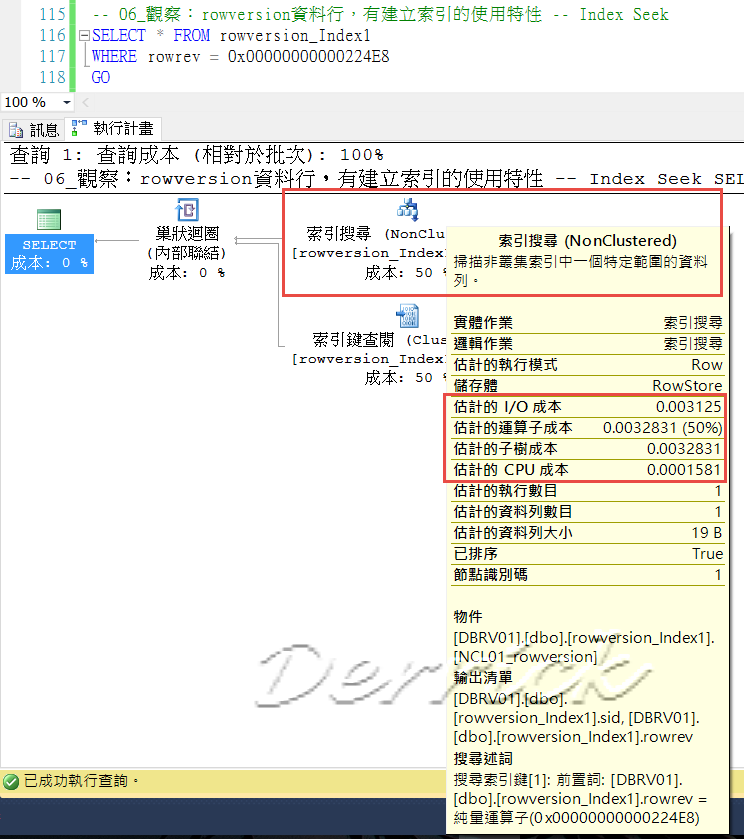
-- P06_WHERE 查詢方式,使用 大於
-- P07_WHERE 查詢方式,使用 等於
-- P08_pid值有重複,觀察資料類型 rowversion 值的特性
-- P09_更動多筆資料列,資料類型 rowversion 的值,已經自動變更
-- P10_不得直接對 rowversion 資料行新增資料
-- P11_不得直接對 rowversion 資料行執行UPDATE
認識 資料類型:rowversion
不可為 Null 的rowversion 資料行,語意等於 binary(8) 資料行。
可為 Null 的 rowversion 資料行,語意等於 varbinary(8) 資料行。
此資料類型會公開在資料庫中自動產生的唯一二進位數字。
rowversion 通常用來做為版本戳記資料表資料列的機制。
儲存體大小是 8 位元組。
rowversion 資料類型只是會遞增的數字,因此不會保留日期或時間。
若要記錄日期或時間,請使用 datetime2 資料類型。
每個資料庫都有一個計數器,會針對在資料庫內包含 rowversion 資料行的資料表所執行的每個插入或更新作業而累加。
這個計數器是資料庫資料列版本。
這會追蹤資料庫內的相對時間,而不是可關聯於時鐘的實際時間。
資料表只能有一個 rowversion 資料行。
每次修改或插入含 rowversion 資料行的資料列時,都會在 rowversion 資料行中插入累加的資料庫資料列版本值。
這個屬性會使 rowversion 資料行不適合做為索引鍵 (尤其是主索引鍵) 的候選項。
資料列的任何更新都會變更資料列版本值,因而會變更索引鍵值。
如果資料行在主索引鍵中,舊的索引鍵值便不再有效,參考舊值的外部索引鍵也不再有效。
如果動態資料指標參考資料表,所有更新都會變更資料列在資料指標中的位置。
如果資料行在索引鍵中,資料列的所有更新也會產生索引的更新。
timestamp 是 rowversion 資料類型的同義字,遵照資料類型同義字的行為。
在 DDL 陳述式中,請盡可能利用 rowversion 來取代 timestamp。
Transact-SQL timestamp 資料類型不同於 ISO 標準中所定義的 timestamp 資料類型。
timestamp 語法已被取代。
未來的 Microsoft SQL Server 版本將移除這項功能。
請避免在新的開發工作中使用這項功能,並規劃修改目前使用這項功能的應用程式。
範例程式碼
-- 01_建立新資料庫
USE master
GO
IF EXISTS (SELECT name FROM sys.databases WHERE name = N'DBRV01')
DROP DATABASE [DBRV01]
GO
CREATE DATABASE DBRV01
GO
-- 02_查詢-目前資料庫的目前 rowversion 資料類型值
USE DBRV01
GO
SELECT @@DBTS N'傳回目前資料庫的目前 rowversion 資料類型值'
GO
-- P01_查詢-目前資料庫的目前 rowversion 資料類型值
-- 03_建立範例資料表,使用資料類型:rowversion
CREATE TABLE rowversion01
(sid int IDENTITY, pid varchar(10), rowrev rowversion)
GO
-- 04_新增資料列,請明確要新增的資料行,
INSERT rowversion01(pid) VALUES('A')
INSERT rowversion01(pid) VALUES('B')
INSERT rowversion01(pid) VALUES('C')
INSERT rowversion01(pid) VALUES('D')
GO
-- 05_查詢資料
SELECT * FROM rowversion01
GO
-- P02_資料行rowversion,自動產生的唯一的二進位數字
-- 06_加入對資料類型 rowversion 的排序
SELECT * FROM rowversion01
ORDER BY rowrev DESC -- 可以排序
GO
/*
觀察
資料行 pid 值為 C,,其 rowrev 值是 0x00000000000007D3
*/
-- P03_加入對資料類型 rowversion 的排序
-- 07_修改pid資料行,由 C 改為 S。
UPDATE rowversion01
SET pid = 'S'
WHERE pid = 'C'
GO
-- P04_資料行 pid 值為 C,,其 rowrev 值是 0x00000000000007D3
-- 08_查詢資料表
SELECT * FROM dbo.rowversion01
ORDER BY rowrev DESC
GO
/*
觀察
資料行 pid 值為 C,,資料類型 rowversion 的值,已經自動變更為 0x00000000000007D5
*/
-- P05_rowversion值,自動更新
-- 09_加入篩選條件式:WHERE 查詢方式,使用 大於(>)
SELECT * FROM dbo.rowversion01
WHERE rowrev > 0x00000000000007D2
GO
-- P06_WHERE 查詢方式,使用 大於
-- 10_加入篩選條件式:WHERE 查詢方式,使用 等於(=)
SELECT * FROM dbo.rowversion01
WHERE rowrev = 0x00000000000007D2
GO
-- P07_WHERE 查詢方式,使用 等於
-- 11_新增資料列,pid值有重複,測試若 UPDATE更新多筆資料列時,資料類型 rowversion 值的特性
INSERT rowversion01(pid) VALUES('B')
INSERT rowversion01(pid) VALUES('B')
INSERT rowversion01(pid) VALUES('B')
GO
-- 12_查詢資料表
SELECT * FROM dbo.rowversion01
GO
/*
觀察
資料行 pid 值為 C,,資料類型 rowversion 是:
0x00000000000007D2、0x00000000000007D6、0x00000000000007D7 與 0x00000000000007D8
*/
-- P08_pid值有重複,觀察資料類型 rowversion 值的特性
-- 13__修改pid資料行,由 B 改為 T,預估有四筆資料列會受到影響
UPDATE rowversion01
SET pid = 'T'
WHERE pid = 'B'
GO
-- 14_查詢資料表
SELECT * FROM dbo.rowversion01
GO
/*
觀察
資料行 pid 值為 C,,資料類型 rowversion 的值,已經自動變更為:
0x00000000000007D9、0x00000000000007DA、0x00000000000007DB 與 0x00000000000007DC
-- 原本
資料行 pid 值為 C,,資料類型 rowversion 的值:
0x00000000000007D2、0x00000000000007D6、0x00000000000007D7 與 0x00000000000007D8
*/
-- P09_更動多筆資料列,資料類型 rowversion 的值,已經自動變更
-- 15_不得直接對 rowversion 資料行做任何異動,例如:不得 INSERT、UPDATE。
INSERT dbo.rowversion01(pid, rowrev) VALUES('E', 0x00000000000007DE)
GO
/*
錯誤
訊息 273,層級 16,狀態 1,行 118
無法將明確值插入時間戳記資料行。請使用 INSERT 配合資料行清單排除時間戳記資料行,或者將 DEFAULT 插入時間戳記資料行。
*/
-- P10_不得直接對 rowversion 資料行新增資料
-- 16_不得直接對 rowversion 資料行做任何異動,例如:不得 INSERT、UPDATE。
UPDATE rowversion01
SET rowrev = 0x00000000000007E2
WHERE pid = 'D'
GO
/*
錯誤
訊息 272,層級 16,狀態 1,行 129
無法更新時間戳記資料行。
*/
-- P11_不得直接對 rowversion 資料行執行UPDATE
參考資料
rowversion (Transact-SQL)
https://msdn.microsoft.com/zh-tw/library/ms182776(v=sql.120).aspx
HOW TO: 使用時間戳記資料行中使用視覺化 C#.NET 的 ADO.NET 偵測更新衝突
https://support.microsoft.com/zh-tw/kb/317095
Optimistic Concurrency in Entity Framework Code First
http://www.codeproject.com/Articles/817432/Optimistic-Concurrency-in-Entity-Framework-Code-Fi
Database Concurrency Conflicts in the Real World
http://www.codemag.com/article/0607081